MLOps
In this module, we introduce concepts and techniques related to MLOps, that is, the automation of operations involved in ML pipelines for applications. By the end of this module, students should be able to:
Describes the basics of the entire ML application workflow and lifecycle.
Implement deployment automation for an arbitrary ML model using Python, Flask, and Docker.
Implement deployment automation for Tensoflow models using Tensorflow serving.
The ML Lifecycle and MLOps
Just like any other software, applications developed with machine learning are products that evolve over time. We repeatedly update the software as we gather more data, develop better models and generally make improvements.
MLOps is a modification of the concept of DevOps, a set of techniques and best practices that originated in the late 2000s with the organization of DevOpsDays (2009) and related events. DevOps is a combination of the terms software development and IT operations, and the idea was to shorten the time between when new software features were developed (i.e., new code being written) and when those features would be released and available to users. In order to shorten that time window, a number tasks needed to be automated, including:
Building/compiling software binaries, and/or assembling software packages.
Running tests on the new software to ensure it was high quality.
Integrating the software with other components in the ecosystem (e.g., other microservices in a microservice architecture) and running integration tests across the entire system.
Deploying the tested code to production.
MLOps modifies the concept to DevOps concept to accommodate the processes involved with building and deploying new ML applications. At a high-level, the life cycle consists of:
Data collection and preprocessing: as we have seen, large amounts of high-quality data is essential to training models that can make accurate predictions.
Model training: Once we have gathered and preprocessed data, we train our model. As we have seen, this can involve lengthy executions to search across different model types and hyperparameter spaces.
Model evaluation and validation: As we train new versions of our model, we evaluate them using various metrics (e.g., accuracy, precision, recall, F1, etc.). Beyond evaluating models against specific metrics, a number of additional validation steps can be taken, including: automated testing, to ensure the application works as intended on important and/or edge cases; fairness/bias assessment, for example, by evaluating your model against a separate hold out dataset that is specifically engineered to ensure that it is representative and inclusive of all perspectives.
Model deployment: after a model version has been validated, we are ready to package and deploy it, either to a pre-production environment such as a test of QA environment, or to production.
Integration Testing, Acceptance Testing, and other automated testing: typically, the trained mode is first deployed to a test or QA environment where automated tests are run. Various kinds of tests could be run, including integration tests (to test the ML model’s integration into the rest of the application), functional or acceptance testing, to evaluate high level functions of the application, and performance and/or load testing, to ensure the application perfoms well under various loads. If the testing produces acceptable results, the model is then deployed to production.
Production Monitoring: once an ML model has been deployed to production, it must be monitored just like any other application component. The model will see new data samples in production, and these should be collected and evaluated. Various changes in the environment, referred to as drift can cause model performance to degrade. For example, some facial recognition systems saw preformance degradation during the pandemic as a result of people wearing masks. Language models see performance degradation over time due to the introduction and use of new words.
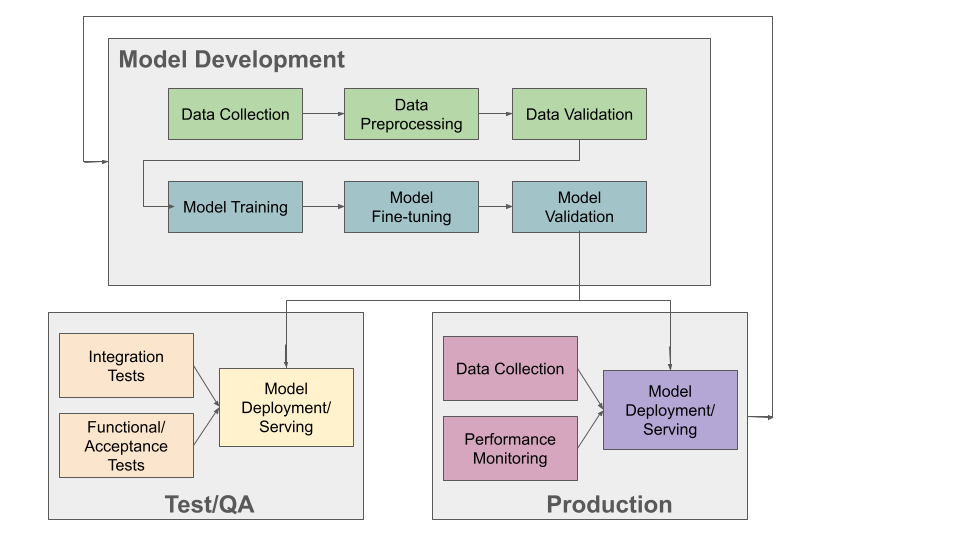
The ML Application Development and Operations Lifecycle
So far in this course, we have mostly focused on 1), 2) and 3). Below, we discuss specific techniques for Model Deployment.
Model Deployment
There are a number of considerations when planning a model deployment. At a minimum, the software must be packaged and delivered in a way that allows it to be utilized by the rest of the application.
Inference Server
The concept of an inference server has gained traction in the ML community. The idea is to wrap the trained ML model in a lightweight server that can be executed over the network. Commonly, this is done either as an HTTP 1.x/REST API or an HTTP 2/gRPC server.
For example, a REST API inference server for the model we developed to classify images with clothes objects may have the following endpoints:
Route |
Method |
What it should do |
|
GET |
Return basic information about v1 of model |
|
POST |
Classify clothes object in image payload using version 1 (v1) of the model. |
When a client makes an HTTP POST request to /models/clothes/v1 they send an image as part of the
payload. The inference server must:
Retrieve the image out of the request payload.
Perform any preprocessing necessary on the image byte stream.
Apply the model to the processed image data to get a classification result.
Package the classification result into a convenient data structure (e.g., JSON).
Send a response with the classification data structure included as the message body.
As you can see, we have encoded both the kind of model (“clothes”) as well as the version (“v1”) into our URL structure. This means that if we developed another model, for example, our handwritten digits classifier, we could easily add it to our inference server. We could also easily add a new version of the clothes model and serve both at the same time.
There are a number of advantages to using an inference server architecture, many of which are just the advantages enjoyed by all HTTP/microservice architectures:
Framework agnostic: Regardless of which ML framework your model is developed in, it can be packaged into an inference server. With that said, some solutions are framework-specific. In fact, one of the solutions we’ll look at is Tensorflow Serving, which serves Tensorflow models (and other kinds of servables).
Language agnostic API: Components of the application can interact easily with the inference server, regardless of the programming language they are written in, because all modern languages have an HTTP client.
Scalability: Multiple components of the application can interact with the model inference server, even from different computers. Additionally, multiple instances of the inference server itself can be deployed to increase the throughput of inferences.
Plug-and-play and model chaining: The concept of plug-and-play for ML models is the idea or goals of enabling different models to be “plugged” into an application with little to no code changes to the rest of the application. In order to achieve this, different models that perform the same (or similar) task must conform to a common interface. An HTTP interface is one possible mechanism. Similarly, model chaining is the idea that we can feed outputs of one model as inputs to another model. For example, we may have one model that finds language characters in an image and another model that translates words from one language to another (for example, Google image translate). If individual models use HTTP requests and responses, the responses from one model can be easily fed into as a request to the next model.
Versioning: There are multiple, intuitive ways to version a model inference server. One which was suggested above is to use the URL to encode the version. These methods will be familiar to most developers, as REST APIs (and HTTP services more generally) have become common in cloud computing.
What do we need to build an ML inference server? The basic ingredients are as follows:
Serialize and deserialize trained models — we saw how to do this with sklearn, but we will quickly see how to do this with Keras.
Write the inference server code — we will see two methods for doing this, including a “generic” method using flask and a Tensorflow-specific method (Tensorflow Serving)
Package the server as a docker container image — This will simplify deployment and make our server more portable.
Deploy the server as a container — We can use a simple script, docker-compose, or something more elaborate such as Kubernetes.
Serializing and Deserializeing Tensorflow Models
In Unit 2 we showed how to use the Python pickle module to serialize a skelearn model. For serializing a
Tensorflow model, we recommend using the built in model.save() method. In general, attempting to use
pickle on Tensorflow models can lead to errors related to model objects not being pickleable.
We’ll illustrate the techniques in this section using a model trained against the MNIST fashion dataset. Recall that dataset consisted of 28x28 grey scale images containing different articles of clothing, and our goal was to build a model that could perform image classification to determine the type of clothing in the image.
We built a few different model architectures. Here I will work with the LeNet-5. We collect the essential code for building the model below:
import keras
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
# Importing all the different layers and optimizers
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, AveragePooling2D
from keras import layers
from keras import models
from tensorflow.keras.optimizers import Adam
from keras.applications.vgg16 import VGG16
# data load
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# normalize
X_train_normalized = X_train / 255.0
X_test_normalized = X_test / 255.0
# Convert to "one-hot" vectors using the to_categorical function
num_classes = 10
y_train_cat = to_categorical(y_train, num_classes)
# Intializing a sequential model
model = models.Sequential()
# Layer 1: Convolutional layer with 6 filters of size 5x5, followed by average pooling
model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(AveragePooling2D(pool_size=(2, 2)))
# Layer 2: Convolutional layer with 16 filters of size 5x5, followed by average pooling
model.add(Conv2D(16, kernel_size=(5, 5), activation='relu'))
model.add(AveragePooling2D(pool_size=(2, 2)))
# Flatten the feature maps to feed into fully connected layers
model.add(Flatten())
# Layer 3: Fully connected layer with 120 neurons
model.add(Dense(120, activation='relu'))
# Layer 4: Fully connected layer with 84 neurons
model.add(Dense(84, activation='relu'))
# Output layer: Fully connected layer with num_classes neurons (e.g., 10 for MNIST)
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
model.fit(X_train_normalized, y_train_cat, validation_split=0.2, epochs=20, batch_size=128, verbose=2)
The output will look similar to the following at the bottom:
. . .
Epoch 18/20
375/375 - 3s - 7ms/step - accuracy: 0.9130 - loss: 0.2334 - val_accuracy: 0.9043 - val_loss: 0.2704
Epoch 19/20
375/375 - 3s - 7ms/step - accuracy: 0.9161 - loss: 0.2265 - val_accuracy: 0.9043 - val_loss: 0.2703
Epoch 20/20
375/375 - 3s - 7ms/step - accuracy: 0.9174 - loss: 0.2215 - val_accuracy: 0.9022 - val_loss: 0.2695
It’s possible that a few more epochs might improve performance, but we’re over 90% accuracy on both the train and validation sets, and the validation accuracy has started to plateau, so this seems like a good time to save the model.
We use the model.save() function, passing in a file name to use to save the model. I will use
the simple name clothes.keras. It is a good habbit to save the models with a .keras extension.
model.save("clothes.keras")
There should now be a file, clothes.keras in the same directory as the notebook you are writing.
If we inspect this file, we will see that it is a zip archive and about 550KB:
$ file clothes.keras
clothes.keras: Zip archive data, at least v2.0 to extract
Note
Keras supports multiple file format versions for saving models. The latest version, v3, will automatically be used whenever the file name passed ends in the “.keras” extension. From the official docs:
“The new Keras v3 saving format, marked by the .keras extension, is a more simple, efficient format that implements name-based saving, ensuring what you load is exactly what you saved, from Python’s perspective. This makes debugging much easier, and it is the recommended format for Keras.”
At this point, we can load our model easily from the saved file into a new Python program. To illustrate, let’s restart our notebook kernel before running the following code.
With our kernel restarted, we’ll use the tf.keras.models.load_model() function to load the model
directly from our archive file. Keep in mind that we will need to re-import tensorflow.
import tensorflow as tf
model = tf.keras.models.load_model('clothes.keras')
Let’s evaluate our model on the training set to convince ourselves that this is indeed our pre-trained model:
# check accuracy on train and test without fitting the model
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
# NOTE: we need to perform the same pre-processing...
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# normalize
X_train_normalized = X_train / 255.0
# Convert to "one-hot" vectors using the to_categorical function
num_classes = 10
y_train_cat = to_categorical(y_train, num_classes)
results_train = model.evaluate(X_train_normalized, y_train_cat, batch_size=128)
print(results_train)
469/469 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.9222 - loss: 0.2040
[0.21835999190807343, 0.9186166524887085]
Indeed, we get 91% accuracy on the training set. We’re ready to build our inference server.
Warning
Be very careful about the version of tensorflow you use to save the model and the version used to load the model. Changing major versions (e.g., tensorflow v1 to v2) can cause the model to fail to load, and even changing from 2.15 to 2.16 because 2.16 introduced a new major version of Keras (v3). See this issue from 3 weeks ago. The safest approach is always to use identical versions when saving and loading.
Developing An Inference Server in Flask
We’ll first look at building an inference server using the Flask framework. This approach is easy to implement and provides us with unlimited customization.
Initial Flask Server
To being, we’ll create a new directory, models, and move our clothes.keras model into it.
We’ll create a file called api.py at the same level as the models directory. The api.py
will contain our Flask code.
We’ll implement two routes, a GET route and a POST route, as per the table above.
The GET will just return information about the model in a JSON object.
Here is the starter code. We’re importing the Flask class and creating the app object, which
is the basic object used for configuring a Flask server. We use the @app.route() decorator
to create a new route, specifying the URL path and HTTP request methods that that route function
should handle. We define a model_info function which just returns a dictionary of metadata
about our model.
from flask import Flask
app = Flask(__name__)
@app.route('/models/clothes/v1', methods=['GET'])
def model_info():
return {
"version": "v1",
"name": "clothes",
"description": "Classify images containing articles of clothing",
"number_of_parameters": 133280
}
# start the development server
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
The code at the bottom just runs the Flask development server whenever our Python model api.py
is invoked from the command line. For more details on Flask, see COE 332
notes or the official
documentation.
Packaging the Inference Server with Docker
Now that we have a minimal server, let’s build a docker image for it so we can test it out. We’ll use a Dockerfile for that. The basic steps are:
Start with an official Python image
Install the Flask library
Copy our source code,
api.pySet the default command in the container to run our program.
Here is the Dockerfile that does that:
# Image: jstubbs/ml-clothes-api
FROM python:3.11
RUN pip install Flask==3.0
COPY api.py /api.py
CMD ["python", "api.py"]
If you need a refresher on Docker, see the COE 332 notes.
To build our image, we use the docker build command. We’ll use the -t flag to tag it with a name.
I’ll use jstubbs/ml-clothes-api. You’ll want to change the name to your own username on Docker Hub.
docker build -t jstubbs/ml-clothes-api .
Now that our image is built,
we can start a container for our inference server using the docker run command. We’ll use the
following flags to that command:
-it: run the container in interactive mode and attach to stdout. This is helpful for seeing the logs from our Flask server.--rm: remove the container once we stop it.-p 5000:5000: map port 5000 in the container to port 5000 on the host. This is important because we want to be able to make requests to our container.
We need to then specify the image name (in my case jstubbs/ml-clothes-api), but we don’t need to specify
a program to run since we set the default command using the CMD instruction in our Dockerfile.
Here is the full command to run our server container:
docker run -it --rm -p 5000:5000 jstubbs/ml-clothes-api
Let’s check that it is working. In another window on your VM, use curl to try the GET route:
curl localhost:5000/models/clothes/v1
{
"description": "Classify images containing articles of clothing",
"name": "clothes",
"number_of_parameters": 133280,
"version": "v1"
}
Looks good! Now, let’s go back and add the inference route.
Adding the Inference Route
Our real goal is to make inference available as a service. For that, we need to add the POST route. That route should take an image, apply the model to it, and return the prediction. We’ll need tensorflow so that we can load and execute the model, and of course, we’ll need our model file. Let’s start by adding those to the Dockerfile.
# Image: jstubbs/ml-clothes-api
FROM python:3.11
RUN pip install tensorflow==2.15
RUN pip install Flask==3.0
COPY models /models
COPY api.py /api.py
CMD ["python", "api.py"]
Back in the api.py file, we need to implement the POST route. We’ll want to load the model
as well. It’s good to load the model on server start up so that the model is ready to go when
a request comes.
As for the implementing the route itself, we have some choices about what kind of data the user will send, with different choices offering pros and cons. For example, we could:
Require the user send a raw image file, such as a png or jpg.
Require the user to send a numpy array, serialized as some kind of binary stream (e.g., using the pickle library)
Require the user to send a JSON list of numbers.
Additionally, within options 2) and 3), we can require the user to preproess the data before sending (e.g., normalizing) or we can perform that function for them. In all three options, we could also consider allowing the user to send a batch of images to inference, instead of just 1.
Option 1) is appealing for some use cases, but for this dataset we load the data directly into numpy
using the fashion_mnist.load_data() function, so in some ways, this option isn’t the most
convenient for our demonstration purposes.
Option 2) is likely more efficient than option 3), but it has the downside of only working for Python clients. If our application will be written in other languages, requiring a numpy array would be overly imposing. It’s also complicated to implement, as we would need client and server to agree on a scheme (e.g., pickling)
We’ll go for option 3). It’s easy, supports multiple languages and lends it self perfectly well to batching, though we won’t implement that here. Instead, we’ll assume the user sends us one image, and we’ll take care of preprocessing it.
To do that preprocessing, we’ll convert the JSON list to a numpy array. We’ll then reshape it so
that it conforms to the shape required for the predict() method (remember, like with sklearn,
the Keras model.predict() function expects a batch of images, so we’ll need to pad an extra
dimension onto the array.)
def preprocess_input(im):
"""
Converts user-provided input into an array that can be used with the model.
This function could raise an exception.
"""
# convert to a numpy array
d = np.array(im)
# then add an extra dimension
return d.reshape(1, 28, 28)
With that code in place, we can write the route. We specify POST as the method and we use
the request.json object, which is a dictionary, to get at the request data. We are assuming
the message contains a single object, image, with the JSON list.
Note that we also handle two errors cases:
The request does not contain json with an
imagefield.The
imagefield cannot be converted to a numpy array and reshaped.
Case 2) causes the preprocess_input() function to raise an exception, so we use a try...except
block.
To apply the model, we use model.predict() on the preprocessed data. Note that the result is a
numpy array, which is not JSON serializable, so at a minimum we’ll need to cast it to a normal Python
list; we do that using the .tolist() method:
@app.route('/models/clothes/v1', methods=['POST'])
def classify_clothes_image():
im = request.json.get('image')
if not im:
return {"error": "The `image` field is required"}, 404
try:
data = preprocess_input(im)
except Exception as e:
return {"error": f"Could not process the `image` field; details: {e}"}, 404
return { "result": model.predict(data).tolist()}
Be sure to add the necessary imports and load the model object. Here is the complete solution:
from flask import Flask, request
import tensorflow as tf
import numpy as np
app = Flask(__name__)
model = tf.keras.models.load_model('models/clothes.keras')
@app.route('/models/clothes/v1', methods=['GET'])
def model_info():
return {
"version": "v1",
"name": "clothes",
"description": "Classify images containing articles of clothing",
"number_of_parameters": 133280
}
def preprocess_input(im):
"""
Converts user-provided input into an array that can be used with the model.
This function could raise an exception.
"""
# convert to a numpy array
d = np.array(im)
# then add an extra dimension
return d.reshape(1, 28, 28)
@app.route('/models/clothes/v1', methods=['POST'])
def classify_clothes_image():
im = request.json.get('image')
if not im:
return {"error": "The `image` field is required"}, 404
try:
data = preprocess_input(im)
except Exception as e:
return {"error": f"Could not process the `image` field; details: {e}"}, 404
return { "result": model.predict(data).tolist()}
# start the development server
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
Testing the Inference Server
We’ll use requests to test our server because it will make it easy to work with the test data.
The process is straightforward — we select an item from the X_test array and cast it to a list
using tolist().
import requests
# grab an entry from X_test -- here, we grab the first one
l = X_test[0].tolist()
# make the POST request passing the sinlge test case as the `image` field:
rsp = requests.post("http://172.17.0.1:5000/models/clothes/v1", json={"image": l})
# print the json response
rsp.json()
{'result': [[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0]]}
Note that our inference server returns the “raw” result of predict(), which is an array.
If we compare that to the actual label, we’ll see that our model got the right answer:
y_test_cat[0]
-> array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.])
Developing An Inference Server with Tensorflow Serving
Tensorflow Serving is a production-ready framework for creating inference servers out of Tensorflow models and other objects. The advantages of Tensorflow Serving are:
It’s already built, so we don’t have to write any code.
It’s maintained by the Tensorflow community, so we don’t have to maintain it.
It’s a high-performance server with many nice features, such as batching and model versioning.
The downsides are:
We have to figure out and conform to the Tensorflow Serving conventions, such as how to save and make the models available to the server.
While many aspects of the server are configurable, we won’t be able to make as many customizations as we are able to with Flask.
The simplest way to use Tensorflow Serving is with the official Docker image, tensorflow/serving
(see [3] for more details).
You can download the image with docker pull:
docker pull tensorflow/serving
One thing to be aware of is that Tensorflow Serving cannot work directly with .keras model files, as
those are zip archives. Instead, it requires them to be unpacked into a directory with a specific structure,
including a directory integer name for the version.
You can generate such a directory using the tf.saved_model.save function on the loaded model (see [2]).
For example:
# load the model from the .keras archive file
model = tf.keras.models.load_model('clothes.keras')
# directory for all of our models
model_dir = "./models"
# version of this model
model_version = 1
# final path
model_export_path = f"{model_dir}/{model_version}"
# call tf.saved_model.save() to create the directory
tf.saved_model.save(
model,
export_dir=model_export_path,
)
If you inspect what tensorflow created for us you will see a file structure like so:
- /models
- /clothes
- /1
- /assets
- fingerprint.pb
- saved_model.pb
- /variables
We can add the models directory to the tensorflow/serving image to serve our model.
We can either create a new image using a Dockerfile and the FROM tensorflow/serving.
To save time, I’ll just mount our model directly into the image (but this is not best practice):
be sure to mount the entire models directory on your host to /models in the container, and
make sure that the folder structure resembles that above or else the Tensorflow Serving server will
not be able to find/process your models.
We’ll also map port 8501 to the host, since that’s the port Tensorflow Serving using by
default, and we’ll aslo need to set the MODEL_NAME environment variable to the name of our model.
docker run -t --rm -p 8501:8501 -v $(pwd)/models:/models/ -e MODEL_NAME=clothes --name mlserve tensorflow/serving
If you see a log such as
E tensorflow_serving/sources/storage_path/file_system_storage_path_source.cc:353] FileSystemStoragePathSource encountered a filesystem access error:
then the server was not able to load your models.
If all goes well, you should see a log like the following at the bottom of the logs:
2024-04-01 01:47:19.900513: I tensorflow_serving/model_servers/server.cc:430] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
Note that you with this solution, will need to perform any preprocessing on the client side.
Inference on Image Files
Keep in mind that for project 3, the dataset consists of “raw” image files. Think through how you want users to interact with your inference server. At a minimum, it needs to be well-documented how to make requests and interpret the responses. Consider developing a small code model and/or convenience functions to use on the client side when interacting with your server. The function might perform the following tasks, given a path to a file on the local disk:
Read the bytes of the file from disk at the path and convert it to a python object (e.g., a numpy array)
Perform any preprocessing needed to that object (for example, adding an empty dimension and/or reshaping the structure so that it conforms to the input shape of your model. You may (or may not) want to perform other kinds of preprocessing, like normalization.)
Convert the structure from step 2) into a JSON structure that your inference server accepts.
Make the HTTP request to your inference server, and parse the response.
Writing a function like the above is also a good way to test your inference server.
Additional References
Machine Learning Systems with TinyML. Chapter 14: Embedded AIOps. https://harvard-edge.github.io/cs249r_book/contents/ops/ops.html#key-components-of-mlops
Tensorflow Documentation, v2.15: tf.saved_model.save. https://www.tensorflow.org/versions/r2.15/api_docs/python/tf/saved_model/save
Tensorflow Serving with Docker. https://www.tensorflow.org/tfx/serving/docker