Linear Regression
In this module, we introduce our first ML algorithm called Linear Regression. We also introduce the SciKit Learn Python library which provides an implementation of Linear Regression and many other ML algorithms.
By the end of this module, students should be able to:
Understand the basics of the Linear Regression model and which ML problems it could potentially be applied to.
Install and import the SciKit Learn Python package into a Python program, and use SciKit Learn to implement a basic Linear Regression model.
Introduction
In Linear Regression, we make the assumption that there is a linear relationship between the dependent and independent variables. To simplify the discussion, we’ll assume for now that there are just two variables, one independent and one dependent.
Recall from the previous lecture that our goal is to model (or predict) the dependent variable from the independent variable. It is customary to use \(X\) for the independent variable and \(Y\) for the dependent variable. To say that there is a linear relationship between \(X\) and \(Y\) is to say that they are related by a linear equation.
We know from elementary algebra that a linear equation has the form
and is uniquely determined by two points \((X_1, Y_1)\) and \((X_2, Y_2)\). This is called the point-slope form of the linear equation. Note that by solving the left-hand side of the equation for \(Y\), we can put the equation in slope-intercept form:
Consider the case of predicting the market value of a piece of real estate. We know in the real world, the value of a property depends on a number of factors, but for simplicity, let us make the assumption that the value is determined by the square footage. Let us further assume that the relationship is linear.
We can restate the remarks above in this context as follows: Given the square footage and value of two properties, we can uniquely determine the linear equation relating square footage and value. Here are two properties in the Austin area that were recently listed on the MLS:
Property 1: 1,007 square feet; $320,000
Property 2: 2,202 square feet; $561,000
We can simplify the data slightly be dividing by 1,000.
Therefore, we can think of these properties as corresponding to the points \((1, 320)\) and \((2.2, 561)\) which leads to the system of equations:
and then to the formula \(Y = 200.83(X - 1) + 320\) which we can visualize as follows:
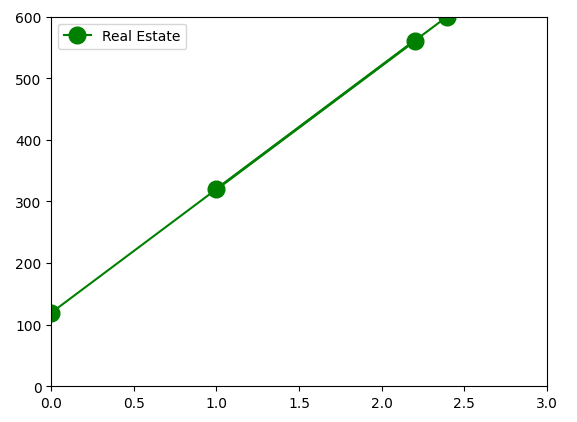
Congratulations! In some sense, this is our very first linear model. It models the value of a real estate property (the \(Y\) variable) as a linear function of square footage (the \(X\) variable).
Using this formula, we could predict the value of another property based on its square footage. Here are some additional properties. How does our model perform?
Property 3: 2,550 square feet; actual value: $590,000; predicted value: ?
Property 4: 3,202 square feet; actual value: $910,000; predicted value: ?
Property 4: 1,500 square feet; actual value: $1,120,000; predicted value: ?
Solution:
We plug the points into the equation \(Y = 200.83(X - 1) + 320\) and compute \(Y\):
Property 3: Predicted Value = \(200.83(2.5-1) + 320 = $621,245\)
Property 4: Predicted Value = \(200.83(3.2-1) + 320 = $761,826\)
Property 5: Predicted Value = \(200.83(1.5-1) + 320 = $420,415\)
If we add these additional data points to our plot, we see that our model did pretty well on Property 3, less good on Property 4, and was completely wrong about Property 5.
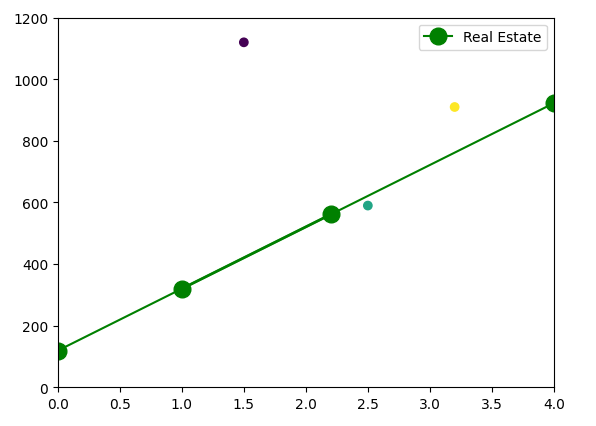
Incorporating Additional Data
There are two main problems with our initial approach.
The first issue is that the linear model we generated was based on the data of just two properties. The MLS lists thousands of properties in the Austin area. Shouldn’t we try to somehow create the model based on as much of that data as possible?
Note
In machine learning, there is typically an assumption that incorporating more data into the model training process will produce a more accurate model.
However, if we try to add even a third point to our linear equation we run into issues: the first two points uniquely determined the line. Put another way, there is no simultaneous solution to the equations:
These equations are just the result of entering the three properties (i.e., \((1, 320)\), \((2.2, 561)\) and \((2.55, 590)\)) into the general form \(Y - Y_1 = m(X- X_1)\).
In mathematics, we say that such a system of equations os overdetermined; i.e., there are more equations than unknowns, and such systems typically have no solution. In general, when working with real-world data we will not be able to find exact solutions to the set of model equations.
Instead, with Linear Regression, the basic idea is to find a linear equation that, when used to predict the dependent variable of the known data points, minimizes a cost function. The cost function is related to another function, called the error function, which is also called a loss function. The error function assigns an error to each data point, and the cost function aggregates these errors across a set of data points.
There are different ways to define the error function, but conceptually, the error function will be similar to the difference between the predicted value and the actual value. Similarly, there are different ways to define the cost function using the error function, but one way is to just add up the errors of all data points in our training set.
Of course, the difference could be positive or negative, and if we just add up the differences, the positive and negative values could cancel each other out, so instead of just summing the errors, one can sum up the squares of the errors. Finally, since summing all of the errors will result in a larger cost for increases in the size of the data set, we want to take an average instead. That leads to the following equation for cost:
The equation above says that the cost associated with a model, \(M\), is given by the sum of the squares of the differences between the actual value and the model’s predicted value across the elements \(d\) in a dataset, \(D\), divided by the total size of \(D\). This approach is called the least squares approximation of the linear model.
Finding the Linear Model Algorithmically
How do we find the linear model, \(M\), that minimizes the cost function, \(Cost(M)\)? We’ll try to provide the basic idea of what is involved, though we don’t give full details in this section.
Recall that the model, \(M\), is defined by just two parameters, the \(m\) and \(B\) in the slope-intercept form:
So, our goal is to find \(m\) and \(B\) that minimizes \(Cost(M)\). To simplify the discussion, let us assume that \(B=0\) (the y-intercept).
Suppose we have \(n\) data points in our data set: \((x_1, y_1), ..., (x_n,y_n)\). Then the cost is a function of \(m\) and \(B\) as follows:
Since we are assuming \(B=0\), we are left with:
But all of the \(x_j, y_j\) are known values coming from points in our dataset, so this is just a quadratic equation in the variable \(m\). From Calculus, we know:
This equation is differentiable,
It will have a minimum where the derivative is 0,
The derivative is a linear function so it will have exactly one zero.
So, it turns out we can find the model that minimizes the cost by finding the zero of a linear function.
Note
The discussion above ignores a lot of details. In practice, a number of additional issues come up. Moreover, there is the matter of how to actually find the zeros of a differentiable function. If you are interested, the Gradient Decent algorithm is a general purpose optimization algorithm for finding the minimum of a differential function. We may provide some details of the Gradient Decent algorithm later in the semester, time permitting.
Note
In the discussion above, we assumed we had just one independent variable (square footage), but similar ideas can be used to deal with the case of multiple independent variables.
SciKit Learn
In this section, we introduce the Python Package SciKit Learn (scikit-learn on PyPI). This
package provides implementations for a number of ML algorithms we will cover in this class.
It also works well with NumPy, Pandas, Matplotlib, etc.
To install scikit-learn using pip:
[container/virtualenv]$ pip install scikit-learn
The main package is the sklearn package; check your installation:
>>> import sklearn
Linear Regression in Sklearn: First Steps
As a first step, let’s create a linear regression model using our real-estate data from above.
To get started, we create a LinearRegression object from the sklearn.linear_model module:
>>> import sklearn.linear_model
>>> lr = linear_model.LinearRegression()
The next step is to fit the model to some data. We’ll go ahead and use all of the data points
from the five properties in the discussion above. We’ll use the .fit() function to fit the model to a collection of data.
Recall we have the following data points representing our 5 real estate properties: \((1, 320), (2.2, 561), (2.55, 590), (3.2, 910)\), and \((1.5, 1120)\).
We need to pass the x values and the y values as separate arrays to the fit() function.
Keep in mind that, in this first example, we have just one independent variable, but in general, there will be multiple independent variables in the data set. For example, we will look at a real estate dataset that has additional variables such as: the age of the structure, the distance to the nearest bus station, the number of convenience stores nearby, etc.
With that in mind, we need to be careful when providing the data to the fit() function. The
LinearRegression class is designed to work for the general case, where there will be many
independent variables. Thus, we pass each x value as an array of (in this case, 1) value, and similarly
for y:
>>> data_x = [[1], [2.2], [2.55], [3.2], [1.5]]
>>> data_y = [[320], [561], [590], [910], [1120]]
# now, we can fit the model to the data
>>> lr.fit(data_x, data_y)
That’s it! With that little bit of code, sklearn executed the least squares approximation algorithm to find the linear model that minimizes the error function.
We can now use the lr object to predict additional values. Suppose we know the values of some
additional properties:
Property 6: 2,300 square feet, $640,000
Property 7: 2,780 square feet, $780,000
We can predict the values using the model’s .predict() function. In general, the
predict() function takes an array of values to predict and returns an array of predictions.
Note also that that the sklearn LinearRegression model is designed for the general
case where one has multiple independent and dependent variables. Therefore, when calling
predict(), we must pass each set of independent variables as an array, even if there is
only one variable/value.
Thus, we’ll call predict as follows – note the use of the 2-d array!:
>>> lr.predict([[2.3]])
--> array([[723.61514037]]
>>> lr.predict([[2.78]])
--> array([[777.13546123]])
Thus, the model predicts that the value of Property 6 will be $723,615 and the value of Property 7 will be $777,135.
Predicting on Test Data and Plotting the Results
We can call the predict() function on an array of data, as follows:
>>> test_data_x = [[2.3], [2.78], [3.5], [1.2], [0.8]]
>>> test_data_y = [[640], [780], [900], [680], [570] ] # actual values
>>> test_predict = lr.predict(test_data_x) # values predicted by model on the test data
Note the shape of the test_predict object:
>>> test_predict.shape
--> (5,1)
We can use matplotlib to visualize the results of the model’s predictions on these test data:
# plot the data
>>> import matplotlib.pyplot as plt
>>> plt.scatter(test_data_x, test_data_y, color="black")
>>> plt.plot(test_data_x, test_predict, color="blue", linewidth=3)
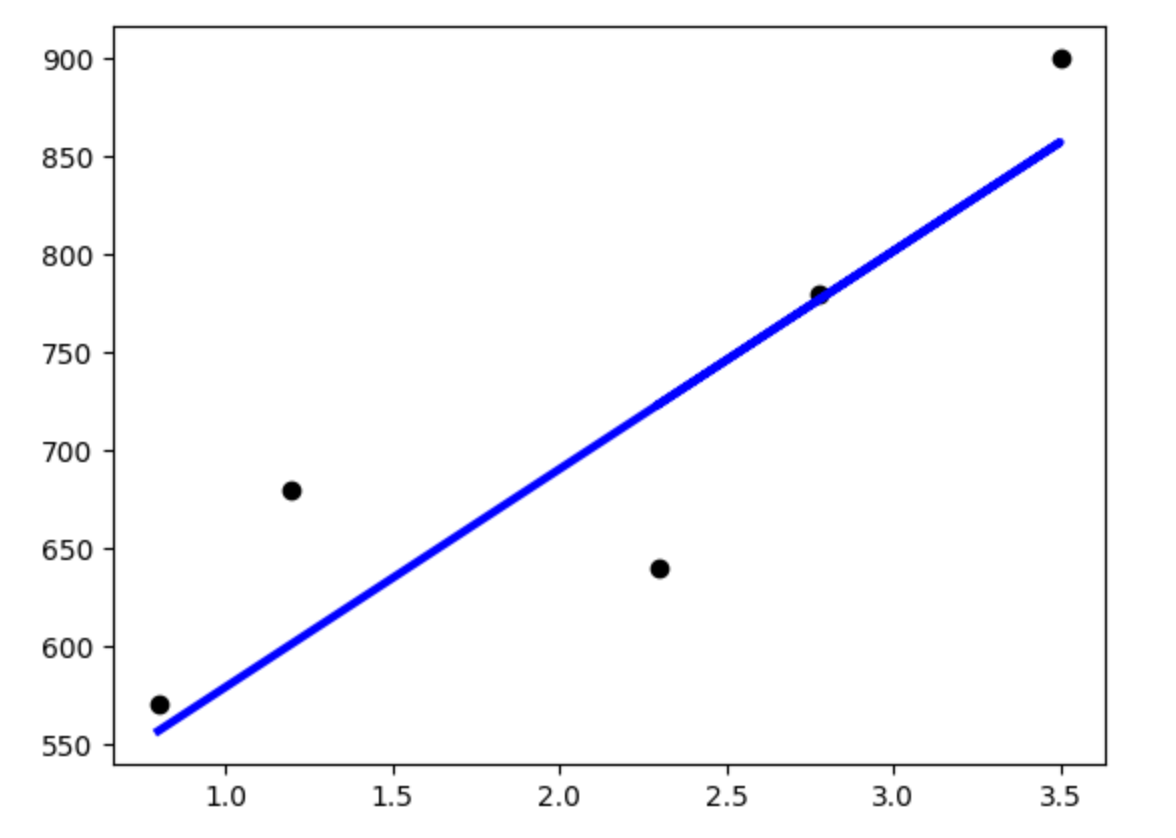
Note that we are using two matplotlib functions here to plot two separate sets of data:
The
scatteris used to simply plot a set of points on an X-Y coordinate plane. In this case, we have usedscatterto display the actual real-estate values.The
plotis used to connect the points with a line. In this case, we have usedplotto display the linear regression model, which of course is a straight line.
Linear Regression with Pandas
We can pass Pandas DataFrames directly to the sklearn functions (e.g., fit() and predict())
once they have been pre-processed.
Let’s try this with our used cars data from unit 1. Recall that we had done a lot of pre-processing work on that dataset. We’ll want to use that here. If we try to use Linear Regression on the original dataset, we will run into all kinds of issues having to do with the fact that the dataset contains non-numeric data.
Note
You can use the output of your own dataset using the df.to_csv() function.
We’ve made an updated version of the dataset available on the class git repository inside unit02 folder. You can download it here.
Either create your own csv from your pre-processing notebook or download the new csv from the website and read it into a DataFrame.
>>> import pandas as pd
>>> cars = pd.read_csv('used_cars_data2.csv')
We can check that our DataFrame has what we expect:
>>> cars.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7178 entries, 0 to 7177
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 7178 non-null object
1 Location 7178 non-null object
2 Year 7178 non-null int64
3 Kilometers_Driven 7178 non-null int64
4 Mileage 7178 non-null float64
5 Engine 7178 non-null float64
6 Power 7178 non-null float64
7 Seats 7178 non-null float64
8 New_Price 7178 non-null float64
9 Price 7178 non-null float64
10 Fuel_Type_Electric 7178 non-null bool
11 Fuel_Type_Petrol 7178 non-null bool
12 Transmission_Manual 7178 non-null bool
13 Owner_Type_Fourth & Above 7178 non-null bool
14 Owner_Type_Second 7178 non-null bool
15 Owner_Type_Third 7178 non-null bool
dtypes: bool(6), float64(6), int64(2), object(2)
memory usage: 603.0+ KB
To use fit(), we need to pass it the independent and dependent variables. If we are trying to
predict Price, what are the dependent and independent variables?
Remember that the Name and Location are not numeric.
Class Discussion. Let’s talk through how to manipulate the DataFrame to specify the X (independent)
and Y (dependent) variables, call fit(), and then use the model to predict some values from
the DataFrame.
Solution:
>>> X = cars.drop(["Name", "Location", "Price"], axis=1)
>>> Y = cars["Price"]
>>> cars_lr = linear_model.LinearRegression()
>>> cars_lr.fit(X, Y)
# be careful of the shape of the object that you pass to predict()
# predict one value...
>>> cars_lr.predict(X.iloc[0:1])
# predict a set of values
>>> cars_lr.predict(X.iloc[0:10])
# How do they compare to the actual values?
>>> print(f"estimated value for car 0: {cars_lr.predict(X.iloc[0:1])}, actual value for car 0: {Y.iloc[0]}")